导读 现在,一种新方法可以通过使用统计机器学习对大量复杂的生物数据进行分类,找到导致疾病的先前未知的因素。这种名为 SLIDE 的旗舰方法成
现在,一种新方法可以通过使用统计机器学习对大量复杂的生物数据进行分类,找到导致疾病的先前未知的因素。
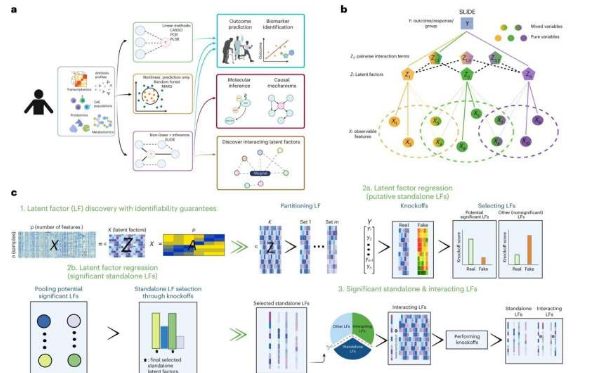
这种名为 SLIDE 的旗舰方法成功地整合了多个复杂的生物数据集,并提取出独特的因素(用英语表示,使结果易于理解),从而直接或间接地解释数据。
康奈尔大学研究人员和康奈尔大学博士表示,它可能会改变我们对多组学数据的看法,即大型且多样化的数据集,其中可以包含有关细胞、组织或个体的遗传学、新陈代谢和功能的详细信息。现在在匹兹堡大学。
他们的研究“幻灯片:跨生物领域的重要潜在因素相互作用发现和探索”发表在《自然方法》上。
“我喜欢它,因为它是可解释的,”合著者、康奈尔大学安·S·鲍尔斯计算和信息科学学院统计和数据科学教授弗洛伦蒂娜·布内亚说。 “本质上,我们可以从可测量的生物输入中找到可解释的隐藏机制。”
该研究建立在包括 Bunea 在内的合著者所做的理论工作的基础上。 Marten Wegkamp,康奈尔鲍尔斯 CIS 统计和数据科学教授以及艺术与科学学院数学教授;辛冰博士是前康奈尔大学统计学博士生,现就读于多伦多大学。
版权声明:本文由用户上传,如有侵权请联系删除!